

機械学習の解釈

はじめに
データサイエンティストの鬼山です。
今回は特徴量重要度やSHAPなど、使ったことはあるけれど中身を理解していない人が意外と多そうな機械学習を解釈する手法について説明します。
機械学習の解釈がなぜ必要か?
解釈可能性(interpretability)、またはほぼ同義で使われる説明可能性(explanability)とはそもそも何でしょうか? 様々な定義が存在しますが、簡単にいうと機械学習のアウトプットやプロセスを人間が理解できることを指しており、以下のような様々な場面で必要・有用なものとなります。
- 説明責任
- e.g. 自動運転において、意図しない運転が行われた理由を説明する必要がある
- 人間との判断の違いの確認
- e.g. 医療診断において、AIの判断の理由がわからないとそのAIの判断が妥当か否か医師が決定できない
- モデルの改善
- e.g. モデルに寄与する特徴量から、特徴量エンジニアリングの仮説を立てる
- アクションへの示唆
- e.g. 売上と広告の関係性を明らかにして、最適な広告投資量を決定する
- モデルに対する信頼/納得感
- e.g. モデルの予測プロセスが現場の経験知と整合的のため、意思決定者が信頼・納得してモデルを採用できる
私の所感として、実務においては「5. モデルに対する信頼/納得感」はあらゆる場面で考慮すべき必要があると感じています。 「1.説明責任」など極めて重要な観点であるものの、必要となる場面が医療や差別など重要な影響が想定されるテーマに限定されます。 一方で、機械学習が実務に適応されるためには関係者に信頼・納得してもらうことはどのようなテーマでも必要で無視できないものとなります。
機械学習を解釈する手法の種類
機械学習を解釈する手法は、個別の予測結果を説明する局所的(Local)な説明手法とモデル全体を説明する大域的(Global)な説明手法の2つに分けられます。 そして大域的な説明手法は、各特徴量が変化した時に予測がどのように変化するのかというやや局所的な説明をする手法と、各特徴量がどの程度予測に寄与するのかというより大域的な説明をする手法の二つにさらに分けることができます。本記事では前者を「中間的な説明」、後者を「大域的な説明(狭義)」と区別して説明します。
- 局所的な説明: 個別の予測結果はなぜそのような予測結果になっているのか?
- 大域的な説明(広義)
- 中間的な説明: 各特徴量が変化した時に予測がどのように変化するのか?
- 大域的な説明(狭義): モデル全体で重要な特徴量は何か?
以下、テーブルデータであるTitanicを利用し各手法について説明します。
局所的な説明
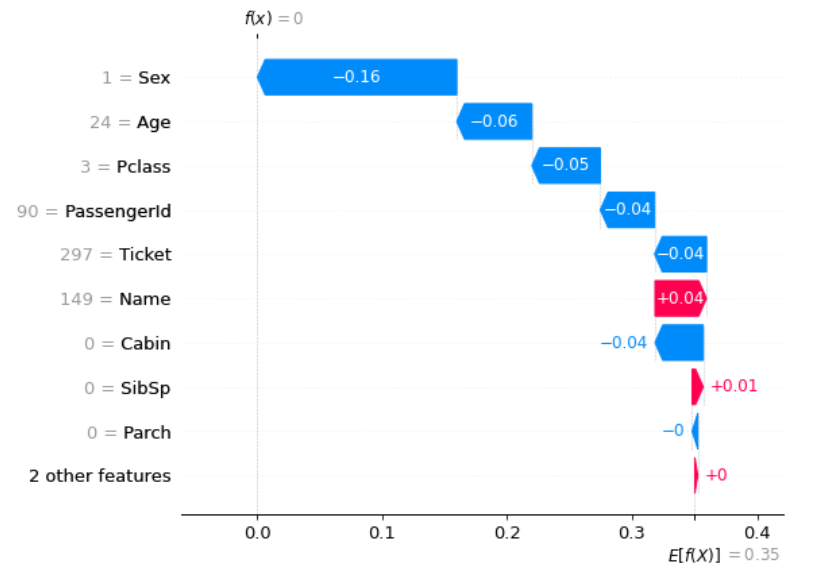
はじめに、個別の予測結果はなぜそのような予測結果になっているのかを説明する手法の代表といえるSHAPについて説明します。
SHAP(SHapley Additive exPlanations)
2017年に提案されたSHAPは、解釈可能性の代表的な研究であるLIMEの発展系として提案されました。 説明したいインスタンス(個別の予測結果)において、各特徴量を平均値に変化させた時の予測値の変化から、特徴量の貢献度を「近似的に計算したShapley値」(SHAP値)により算出します。 (具体的な説明はDataRobot社の記事がわかりやすいです)
局所的な説明を行う手法はSHAP以外にも存在しますが、SHAPの大きなメリットとしては、この局所的な説明を積み上げることにより大域的な説明も可能になる点があります。 この特徴により局所的説明と大域的説明を矛盾なく行うことができます。
一方で、計算量が多い点には留意が必要です。
近似的な計算方法はモデルごとに異なり、決定木系のアルゴリズム(Tree SHAP) では高速かつ正確に計算できるが、アンサンブルモデルなど任意のモデルで利用可能なアルゴリズム(Kernel SHAP)は指数的な計算量となります。
また、データが巨大な場合(数百万行 x 数千列など)は決定木系のアルゴリズムでもそれなりに時間がかかることがあり、探索的なデータ分析を行う際にはボトルネックとなりえます。
中間的な説明
つぎに、各特徴量が変化した時に予測がどのように変化するのかを説明する手法であるPartial Dependence PlotとSHAP Doendence Plotについて説明します。
PDP(Partial Dependence Plot)
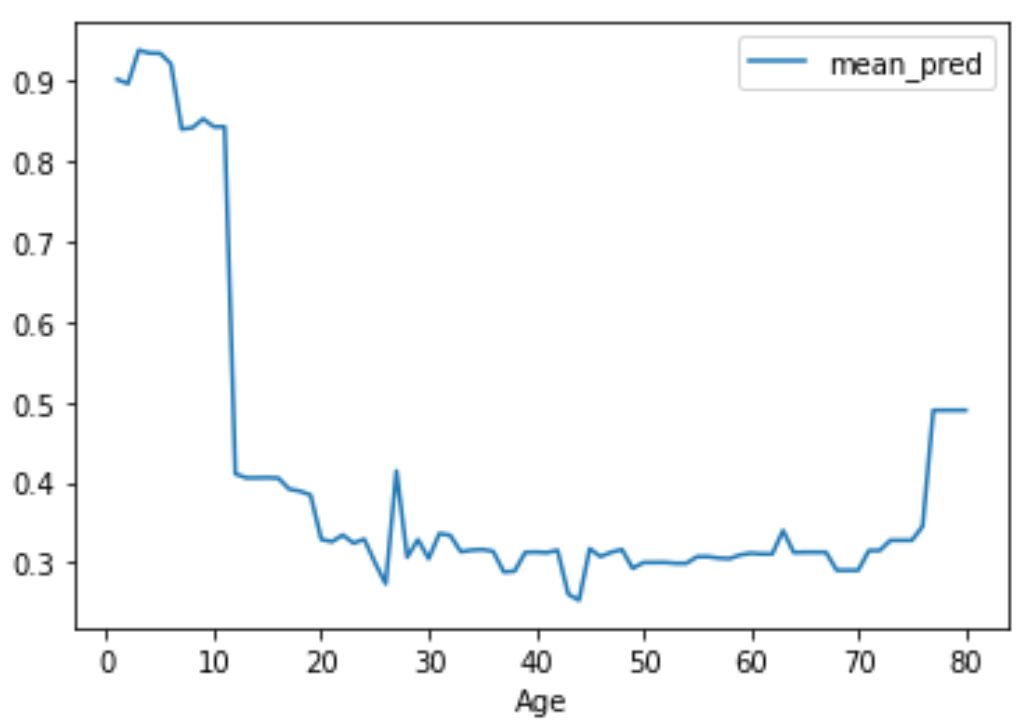
中間的な説明の手法として古典的な手法としてPartial Dependence Plotがあげられます。 他の特徴量を固定した状態で、(通常はある1つの)特徴量について同一の値を全てのレコードに代入した予測値の平均値を計算し、この同一の値を最小値と最大値の間で動かした結果をプロットすることにより特徴量の変化による予測の変化を可視化します。
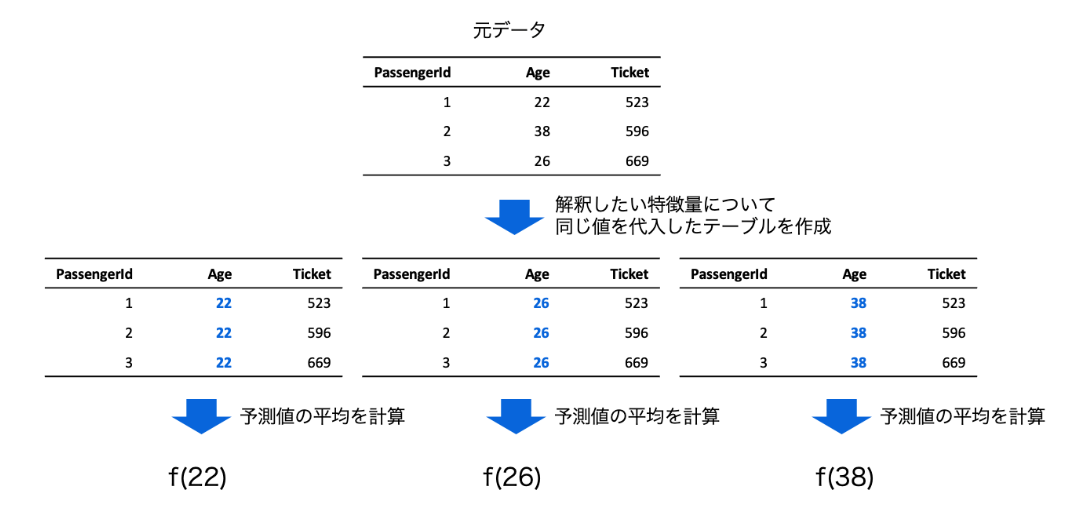
Partial Dependence Plotを用いる利点として、非常に直観的な手法である点が挙げられます。
非専門家に対しても説明を理解してもらうのは比較的簡単といえます。また、計算量が軽く、任意のモデルに対して適応可能な点もメリットとしてあげられます。
一方で、相関のある特徴量がある場合非現実的な特徴量による予測となっている可能性がある点は課題となります。
例えば、身長と体重には一定の相関関係が期待されますが、全ての人に対して最大値となる体重を代入したうえで予測を計算するということが起きてしまいます。
SHAP Dependence Plot
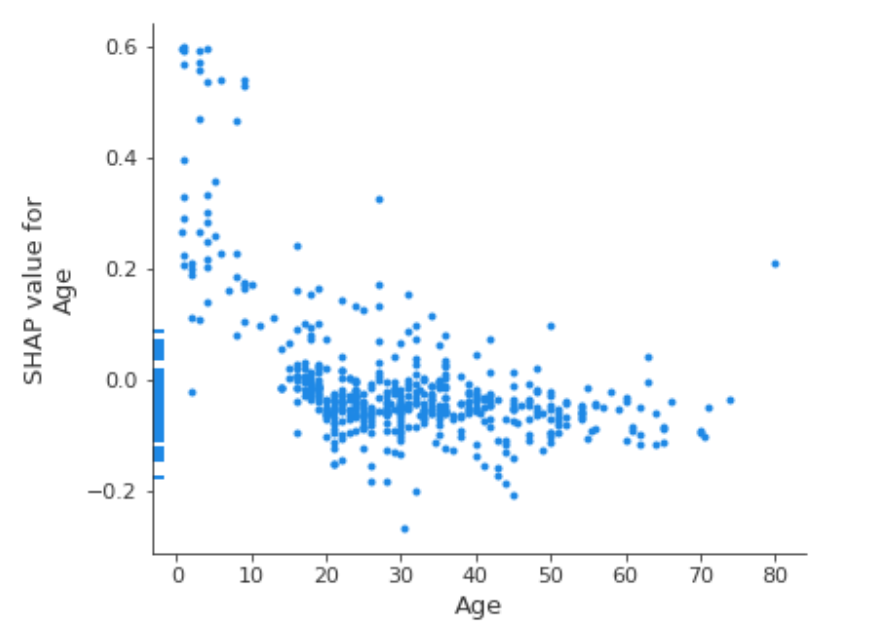
SHAPにおいて中間的な説明をする方法として、単純にインスタンス単位の特定の特徴量の値と対応するSHAP値をプロットする方法があります。 この方法は、SHAP Dependence Plotと呼ばれています。
実際の特徴量の組み合わせに基づいて計算されるため非現実的な特徴量の組みは存在しません。
一方で、Partial Dependence Plotのように他の特徴量を固定した上である特徴量を変化させた時にどのようになるのかというWhat-If的な議論はできない点については留意が必要です。
(ただし、Partial Dependence Plotの結果も因果関係と解釈するには独立性の仮定が必要であり現実的ではありません)
大域的な説明
Split(Weight) Importance
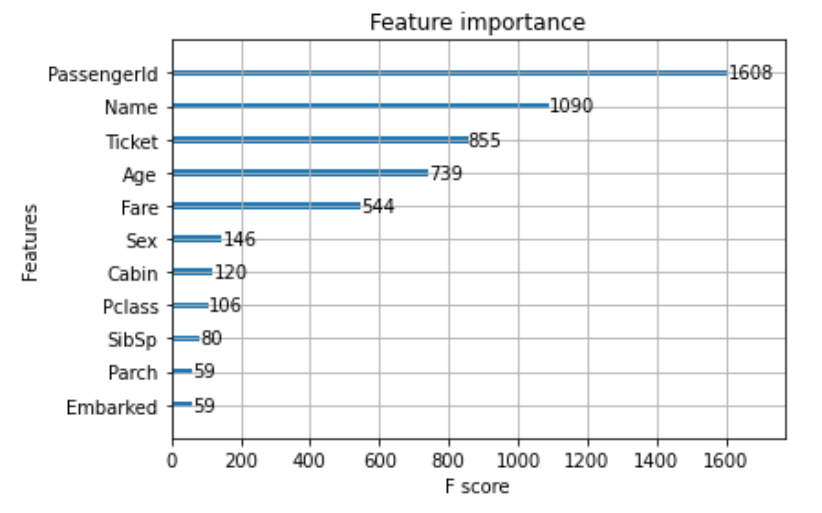
PythonライブラリのLightGBMやXGBoostのPythonライブラリのデフォルトとして採用されているのがSplit(Weight) Importanceです。 これは、ツリーの分割に使用された回数を計算してます。
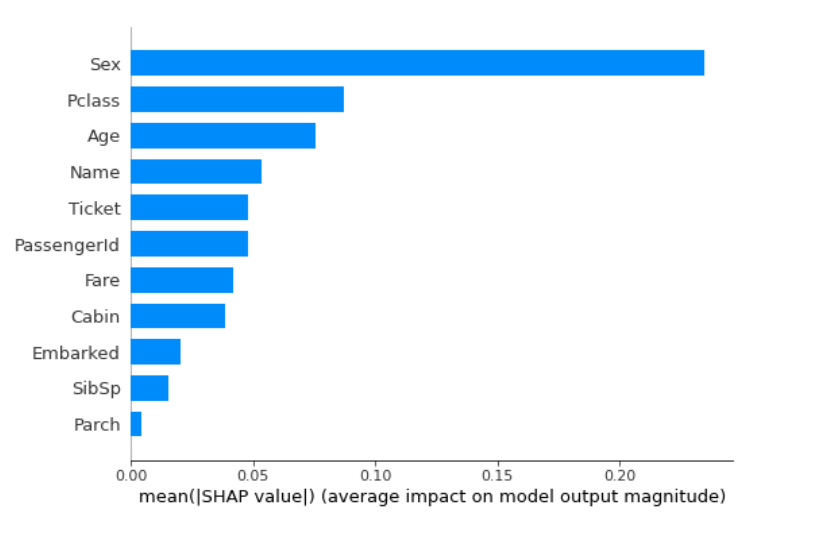
よくも悪くも極めて単純で説明がしやすい一方で、予測に寄与したかを直接的には考慮していないため、カーディナリティの高い(取りうる値の種類が多い)特徴量の重要度が高くなりやすいという致命的な欠点があります。 以下のTitanicデータにおける結果を見ても、後述の他手法と異なりカーディナリティの高い’PassengerId’や’Name’が最も高い結果となっており、できるだけ利用は避けた方が良いと考えられます。
Gain Importance
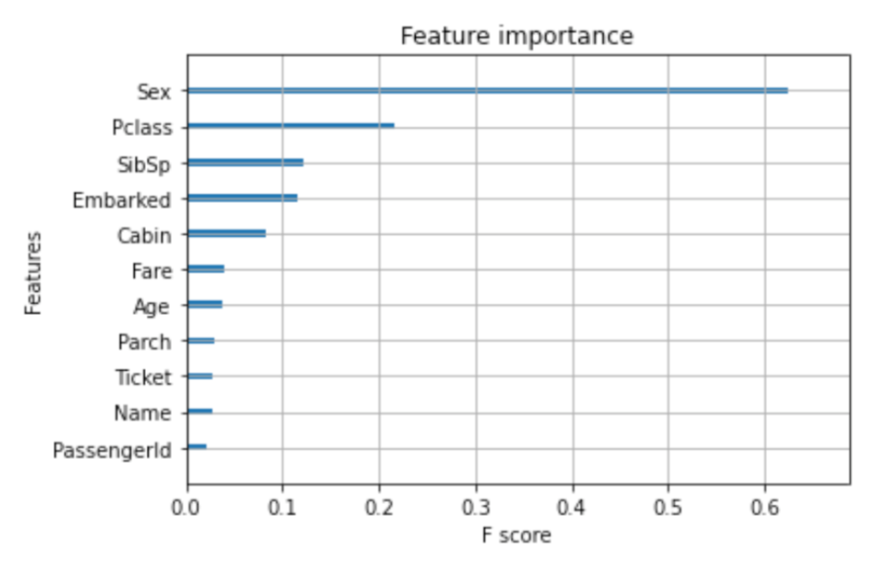
LightGBMやXGBoostのPythonライブラリで利用可能なSplit(Weight) importance以外の手法のひとつとして、Gain Importanceがあります。 Gain Importanceでは、決定木系の手法の各ノードでその特徴量を追加したことによりどの程度予測が向上したかに基づいて重要度を計算します。
結果を見てもわかる通り、Split(Weight) Importanceとは異なり後述の精度に基づいて重要度を算出する手法と同様にカーディナリティの低い’Sex’が最も重要という結果となっていることがわかります。
Gain Importanceを利用する利点としては、LightGBMやXGBoostのPythonライブラリで利用可能な点があります。 importance_type=”Gain”’と指定することにより、他のライブラリを利用せずに容易に可視化することができます。 一方で、決定木系の手法にしか使えない点や後述の手法と比べ得られる情報が少ない点は欠点となりえます。
Permutation Importance
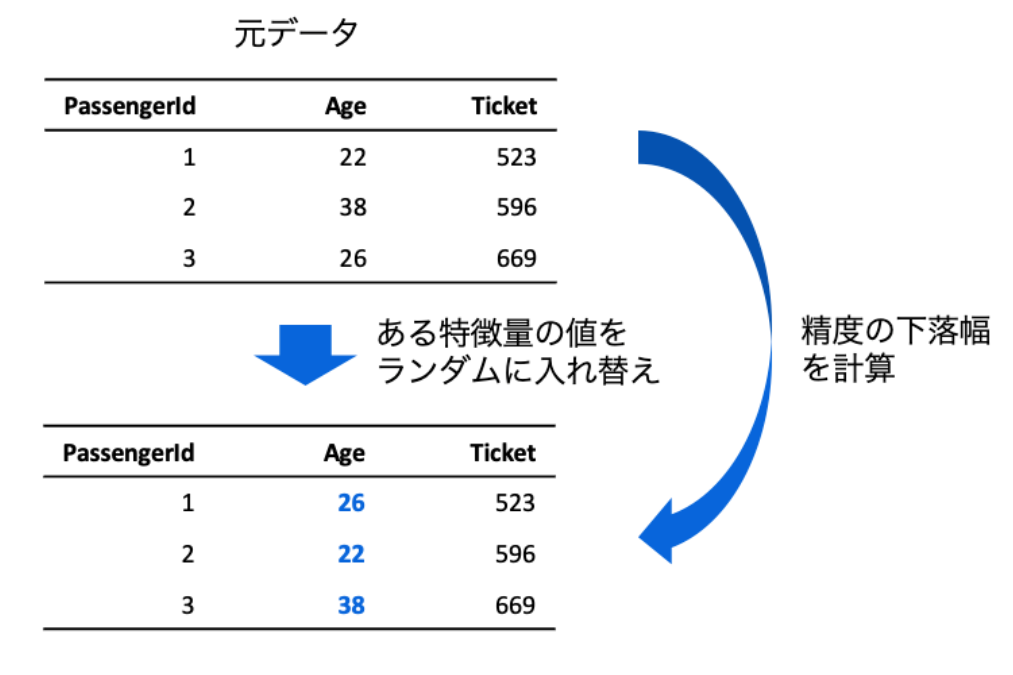
Permutation Importanceは特徴量の値を元のモデルの精度からある特徴量をレコード間でシャッフルした時の精度の下落の大きさを計算することで、シャッフルによりある特徴量を利用しなかった時のモデルの精度を擬似的に計算します。 (ある特徴量を削除しても同様の計算が可能だが、その場合はモデルの再学習が必要であり計算コストが高いため、このような手法を用いています。)
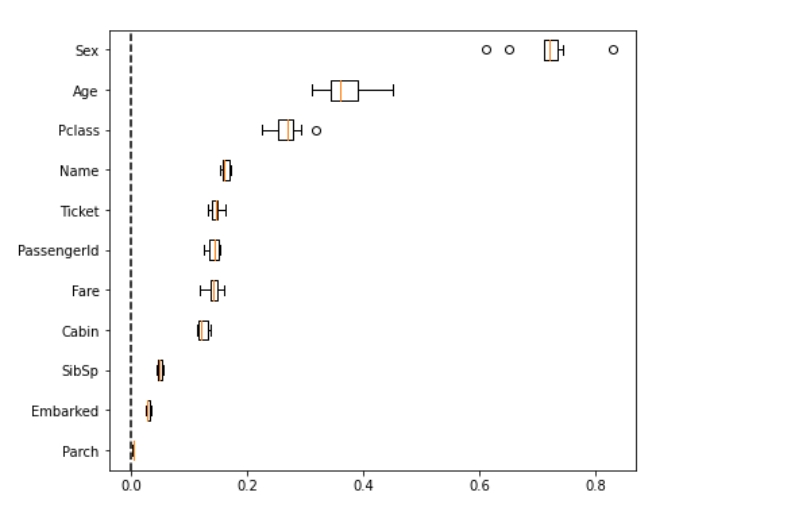
Permutation Importanceの利点として、Partial Dependence Plotと同様に比較的簡単な解釈が可能である・任意のモデルに適応可能である点があげられます。 またランダムにシャッフルを行うため、その重要度が確率的にどの程度確からしいかという点も可視化を行うことができます。
一方で、Premutaiton Imprtanceは特徴量の値をシャッフルする際に自動的に相関関係を破壊するため、相関の強い特徴量間での利用は留意が必要です。 (複数の特徴量を同時に考慮するGrouped Perumtation Importanceという手法も存在しますが、自明に相関する特徴量間(e.g. One-Hot Encoding)にしか適応が難しいでしょう。)
SHAP Importance
SHAPにおいては、特徴量ごとに個別のインスタンスの貢献度の絶対値を平均することでSplit(Weight) ImportanceやGain Improtanceと同様の形式で特徴量重要度を可視化することができます(1つめの図)。
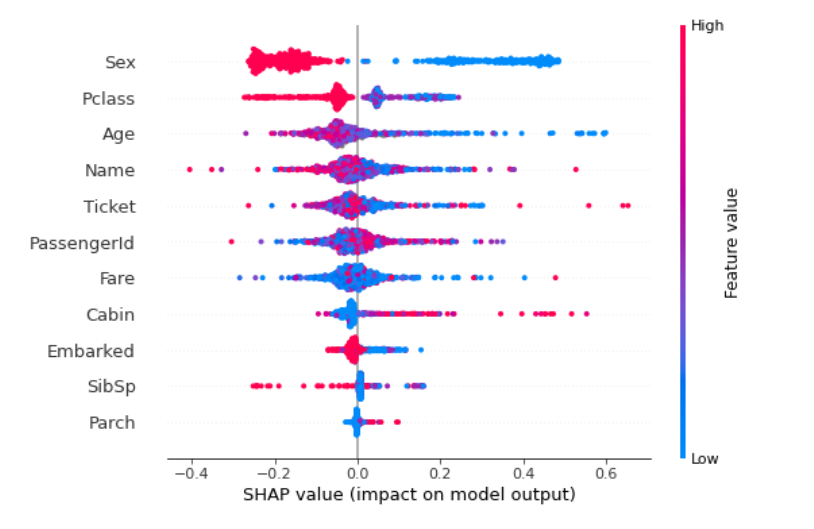
SHAPにしかない利点としてインスタンス間の異質性を考慮することができる点があげられます。 単純にインスタンスごとの寄与度をplotする(2つめの図)ことにより、インスタンスごとの異質性・他の特徴量との相互作用でも可視化することができます(赤・青がはっきり分かれている特徴量は相互作用は少ないが、分かれていない特徴量は相互作用があることが示唆される)。
懸念としては、前述の通りデータ量が巨大な時や決定木系以外の手法においてはSHAPの計算量の高さが課題となる可能性があります。
所感
今まで見てきた通りテーブルデータで広く用いられるLightGBMを代表とする決定木系の手法においては、SHAPが局所的な説明・中間的な説明・大域的な説明の全てに対して適応可能でかつ情報もリッチのため極めて有用であることがわかります。
一方で、SHAPは決定木系以外の手法やデータ量が巨大な場合は計算量により実用性が課題になりえます。
そのような場合は、Partial Dependence Plot・Gain Impotance・Permutation Imporanceなどの比較的古典的な手法も代替の選択肢として考えられます。
参考文献
具体的なコードを含めた文献は[1]、より様々な手法を網羅した文献としては[2]がおすすめです。
- [1]機械学習を解釈する技術
- [2]Interpretable Machine Learning
エムシーデジタルでは、技術力向上のためのイベントや勉強会なども定期的に実施しています。 もしエムシーデジタルで働くことに興味を持っていただいた方がいらっしゃいましたら、カジュアル面談も受け付けておりますので、お気軽にお声掛けください!
採用情報や面談申込みはこちらから




