

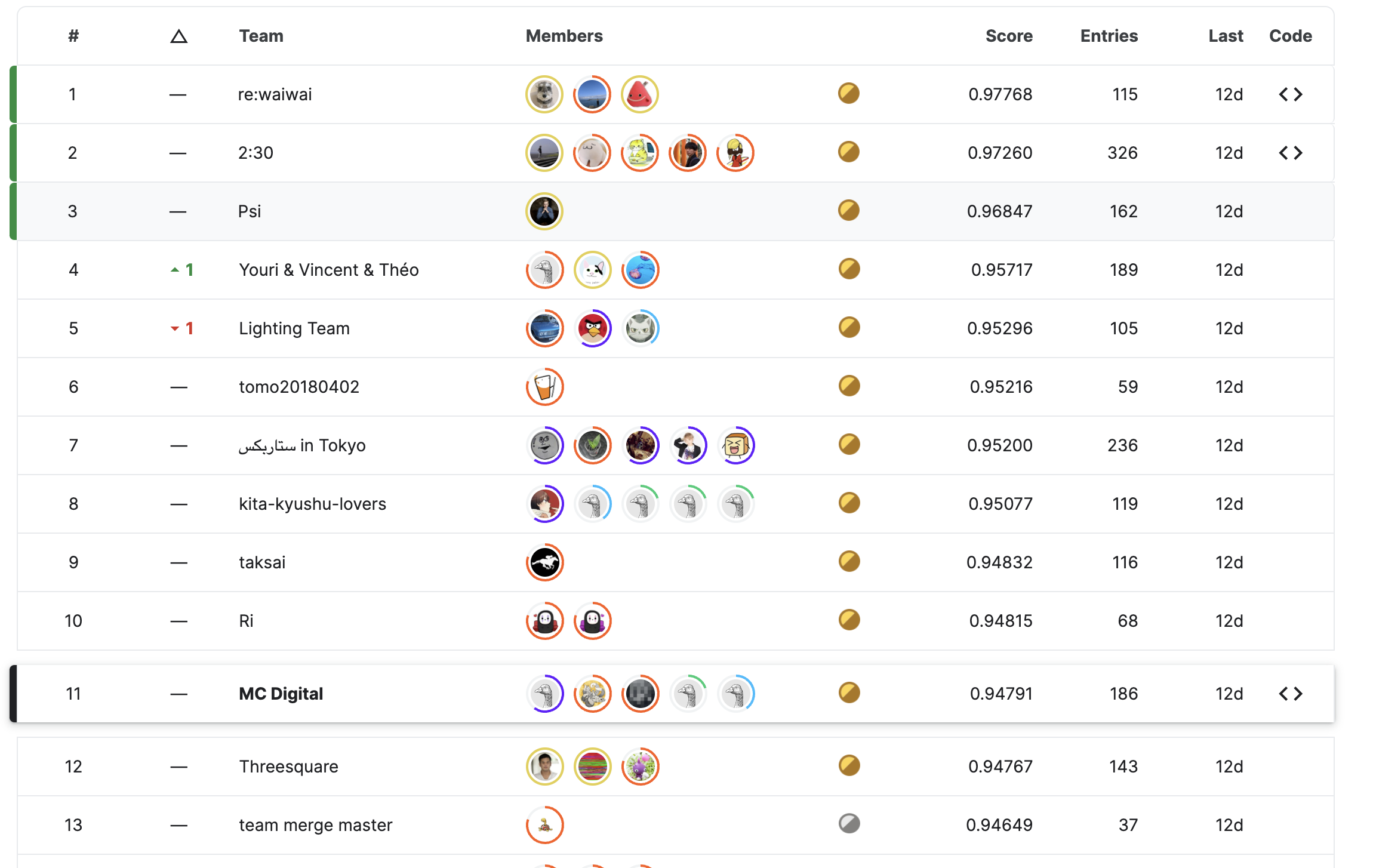
Kaggleの『Foursquare』コンペティションで金メダル(11位/1083チーム)を獲得しました!
初めまして!エムシーデジタルでデータサイエンティストをしている中島です。この2ヶ月の間、弊社5人のチームの一員として『Foursquare』コンペティション(コンペ)に参加しました。テストデータのリークもあり終了後まで波瀾万丈なコンペでしたが、無事に金メダル(11位/1083チーム)を獲得することができました。
この記事では我々チームの取り組みについて紹介します。まずはコンペの概観を見た後、我々のチームの解法について説明します。次に他の上位チームの解法を紹介し、最後にKaggle初参加の立場としてエムシーデジタルチームがどのような雰囲気だったかお伝えしたいと思います。
コンペについて
今回のコンペは point of interest (poi) と呼ばれる地図情報に関するものです。皆さんもGoogle Mapsのような地図アプリでコンビニや公園といった場所のアイコンをクリックしたことがあると思います。このような我々にとって注目する価値のある地図上の場所は poi と呼ばれています。poiの名前・住所・緯度などのデータは経路案内や検索など様々な地図上のサービスの基礎として活用されています。
これらのサービスを機能させるためにpoiのデータセットが整備されてきました。poiのデータセットを使い易いものにするためには、同じpoiが重複しないようまとめていく必要があります。例えば「羽田空港」と「東京国際空港」という2つの地点は、名前は違うものの同じpoiであるためまとめる(マッチさせる)必要があります。このような別名に加えて、不完全だったり不正確な情報があるため、同じpoiをまとめていくのは難しい課題になっています。Foursquare社はこの課題に12年以上にわたって取り組んできた企業です。
今回のコンペの目的は人工的にノイズが加わったデータで、Foursquare社のようにpoiをマッチさせる作業を行うことです。参加者には複数の地点についてその地名・緯度・経度・住所などの情報が与えられます。これらの情報から、与えられた地点のうち同じpoiなものをできるだけ精度良くマッチさせるモデルを学習するのが目標になります。
入力データと出力
まずはデータと出力について説明します。 参加者にはテスト用のデータとして以下の情報を持つ複数の地点が与えられます。
- 名前
- 緯度・経度
- 住所
- 郵便番号
- url・電話番号
- カテゴリー(“Restaurants"など)
データには空欄もあり正確とも限りません。また地名は英語とは限らず、日本語を含め様々な言語が使われています。各地点にはidが割り振られています。
参加者の目標はこれらの情報から同じpoiな地点をマッチさせていくことです。 具体的には、各地点に対して同じpoiである地点のidのリストをできるだけ正確に出力するのが目標です
学習データとしては、上述のテストデータの情報に加えてその地点が属するpoiのidも与えられます。これにより学習データ内の2つの地点が同じpoiかが分かり、モデルの訓練が可能になります。モデルの汎化性能を正しく評価するには、学習データとテストデータは同じpoiの地点を含んでいてはいけません。テストデータは学習データと同じpoiを含んでおらず正当な評価になっていることはコンペの説明でも明記されていました。
評価関数
出力の評価は、各地点について参加者が出力した同じpoiと予測した地点の集合が、実際に同じpoiな地点の集合にどれくらい一致しているかで図られます。具体的には以下で定義される Intersection over Union (IoU)で測られます:
$$ J(A,B) = \frac{|A \cap B|}{|A \cup B|} $$
これは2つの集合が一致しているほど大きい指標で、完全に一致していると1になります。 各地点に対するIoUの平均が最終的なスコアとなります。テストデータ(の一部)に対するスコアはLeaderboard(LB)でコンペ中も確認できます。
課題の難しいところ
このコンペで鍵となるのは、次の三つの難所を解決することです。
- エラーを含んだ文字情報をきちんと取り扱う必要があります。架空の例として、「羽田空港」とそのタイポの「羽空港」はマッチするべきですが、自然言語処理を適切に駆使して同じpoiと判定する必要があります。
- 複数の種類の情報を統合して同じpoiか判定する必要があります。例えば地名や住所は文字情報ですが、緯度や経度は実数の位置情報ですし、電話番号や郵便番号はカテゴリ情報になっています。
- ある地点 $p$ と同じpoiとして出力する地点の集合を求める際に、全ての地点の部分集合を試して一番良かったものを探してくるのは指数時間かかり現実的ではありません。そこで、他の地点$q$ごとに地点$p$とマッチするかをモデルで判定し、マッチ確率が高かったら同じpoiと判定した集合に入れていくという方法が取られます。しかしこの方法は2つ問題があります。
- このコンペでは推論(出力)はKaggle Notebook上で行うため、限られた計算資源しか使えません。そのため全ての2つの地点について同じpoiかを重いモデルで判定するのは実行時間やメモリの制約から不可能です。軽いモデルで同じpoiとなる候補を絞り込んだ後、より正確な重いモデルで判定を行う工夫が必要になります。
- 2点$p$, $q$のみの情報からこれらがマッチするかを判定しようとすると失われてしまう情報があります。例えば別の地点$r$があり、モデルが判定する「$p$と$r$」「$q$と$r$」のマッチ確率が高いなら、$p$と$q$のマッチ確率が低かったとしても実は同じpoiである確率が高いはずです。上述の通り全ての部分集合を試すことはできないものの、2点間のみを考えるのも情報が落ちすぎており、うまくバランスをとったマッチ判定方法を考える必要があります。
リークと訓練データの差し替え
上述した通り、モデルの汎化性能を評価するためには学習データと同じpoiを含んでいないテストデータを使う必要があります。しかしながらコンペ終了後のDiscussionにおいて、実はテストデータと学習データは同じpoiを含んでいることが明らかになりました。他の参加者やKaggle公式からの発表により、以下のような問題があったと確かめられています。
- テストデータの67%の地点が学習データに含まれている
- 推論用のNotebookを提出した後、学習データ(train.csv)が参加者に与えられたものと違うものに差し代わり実行される
第一の問題点のため、各チームのスコアはモデルの汎化性能の指標とはかけ離れたものになってしまっています。いくつかのチームはコンペ終盤にリークに気がつき、明示的に利用してスコアを上げました。また我々を含むリークに気が付かず明示的に用いなかったチームも、知らず知らずのうちに過学習したモデルを提出しリークの影響でスコアを上げてしまっていました。これはLB上のテストデータのスコアを頼りにモデルの選択やハイパーパラメタの調整などを行なった場合、過学習した方がスコアが良く選ばれやすいためです。リークを発見しスコアを上げたチームの観察眼は素晴らしく称賛に値する一方で、汎化性能の高いモデル作りを競いあうという楽しさが毀損されたことは残念に思っています。
第二の問題点はより深刻でコンペの公平性を損なっています。一部のチームは推論時にも学習データを使って特徴量を算出していました。これらのチームのNotebookは、学習データが提出されたNotebookの実行時に指し変わったため、本来意図していなかった動作をし不当にスコアが低くなっていたと考えられます。第一の問題点のようなリーク単体ならkaggleでは(残念ながら)しばしば起こるため、参加者が予想できる範疇であり、あくまでルール内での公平な勝負と言えます。しかし公式の明言なしに学習データが差し代わっているというのは予測できるものではなく、差し替えのせいで提出したNotebookが正しく動作しない事態を見通せなかったとしても参加者に一切非がないものです。このような原因でスコアが変わってしまっているのは勝負の公平性を損なっています。加えて学習データの差し替えはリークに気がつくのも難しくしていました。 差し替え後の学習データはテストデータと重複がなかったため、差し替え前の学習データを保存しておいてアップロードしておかないとリークに気がつくことができませんでした。我々のチームもこのせいでリークがないと判断していました。仮に差し替えがなければ早い段階でリークが公表され、参加者の時間が無駄になることがなかったのではないかと思っています。これらの点からデータの差し替えについては遺憾に思っています。
我々の解法
続いて我々がコンペの課題にどう取り組んでいったかを説明していきます。リークのため残念ながら我々の解法は汎化性能の高いものだったかは分からない状況となっていますが、過学習しているとはいえ全てのアイディアが無意味という訳ではないと考えています。他の状況に活かせることを期待して解説します。
前述の課題の難しいところで説明した三つの課題について、我々は次のように取り組んできました。
- 地名や住所に対する自然言語処理に関しては、Bidirectional Encoder Representations from Transformers (BERT)を用いた距離学習を行い埋込を計算することで取り扱いを行いました。また編集距離などの特徴量も予測に用いています。
- 地名のような言語情報と緯度のような地理情報を統合して扱うため、BERTの出力に緯度・経度の情報を入れて埋込を計算しています。また勾配ブースティング決定木(Gradient Boosting Decision Tree; GBDT)によるマッチ判定の際も埋込・緯度・経度など種々の情報を入れています。
- マッチ判定に関しては以下の工夫をしています
- 計算量を絞るため各地点について同じpoiか判定する候補を、埋込が近い上位50地点と距離が近い上位10地点に絞っています。また近さの順位ごとに同じpoiか判定するGBDTを学習することでデータ量を抑えメモリを節約しています。加えて推論時にはGPUを活用できるForestInference使って高速化しています。
- 3地点以上の情報を使ってマッチ判定するため、GBDTの出力を重みとする有向グラフを作り、各地点間のグラフ上の最短距離を見て最終的なマッチ判定としました。加えて自身より順位が低い候補のGBDTの出力結果もGBDTの特徴量にしています。
我々の解法は大きく分けて4つの段階に分かれています。前処理も踏まえて順番に解説していきます。詳細についてはKaggle Discussionで公開したSolutionも見てください。
前処理
空欄データに関しては緯度・経度が近い5地点のデータで補完しています。
1st Stage: 埋込の計算
まずは各地点の地名・住所のような自然言語情報と緯度・経度のような地理情報から埋込を計算します。埋込の計算には次のようなニューラルネットワーク(NN)を用いています。
- 初めにBERTで地名のような自然言語情報の埋込を得ます
- BERTの出力と緯度・経度の情報を合わせたものを全結合の一層に通します。この出力を2nd stage以降で用いる埋込とします
- 結合の重みは、同じpoiの埋込は近く違うpoiの埋込は遠くなるように学習しました。具体的にはArcMarginProductを誤差関数として学習しています。
埋込の計算ではいくつかの工夫を行なっています
- Database Augmentation (DBA)として、自身に近い埋込との平均を取ったものを最終的な埋込としています。この操作を行うと、同じpoiの地点は埋込が近いはずなので、平均化された埋込はpoiの真の埋込に近くなると期待できます。
- 4つのBERTモデルを用いてアンサンブルしています。
- 学習はfulldataで行なっています。元々は4fold CVを行なっていたものの、LBのスコアがfulldataで学習した方が高かったためそうしています。あとから振り返るとこれはリークのため過学習したモデルの方がスコアが良かったためで、汎化性能は劣化させてしまっていたと考えられます。
2nd Stage: GBDTによるマッチ判定
続いて埋込を用いて2つの地点が同じpoiかを判定します。この判定にはGBDTを用いました。前述の通り全ての地点のペアに対して判定するのは、計算資源の点から現実的ではありません。そのため我々は以下のような処理を行いました。
- 各地点について埋込が近い50地点を候補として挙げます。これに加えて緯度・経度が近い10地点も候補に加えます
- 各候補の地点についてGBDTでマッチ判定を行います。GBDTは埋込の近さの順位ごとに異なるモデルを学習し用います。これは全体のGBDTを学習するより各順位のGBDTごとに学習する方がメモリの節約になるためです。
特徴量では埋込の他に以下のようなものを用いました
- 地名や住所の編集距離
- 自身より順位が小さい地点のGBDTの出力結果の平均
GBDTの学習にはいくつか工夫をしています。
- スコアに用いるIoUは正解の集合の大きさに応じて一件のFPやFNが与える影響が異なるものになっています。そのためpoiの集合の大きさに応じて学習の重みを変更しています
3rd Stage: ダイクストラ法によるマッチ集合の決定
最後にGBDTの出力からグラフを作り、最小距離を使ってマッチ判定を行いました。具体的には各地点をノードとし、GBDTのマッチ確率を$x$とした時$1.0 - x$を重みとする辺を持つようなグラフを考えます。逆辺との重みの平均を取り無向化した後、各地点についてグラフ上の距離が一定以下のものを同じpoiとしてまとめるという処理を行いました。グラフ上の距離の処理ではダイクストラ法を使いました。
スコアの変遷
- 0.922 ベースライン: bert-base-multilingual-cased
- 0.928 +xlm-roberta-base(2アンサンブル)
- 0.931 +GBDT 特徴量の追加
- 0.940 +前処理での空欄埋め
- 0.945 +bertモデルをさらに2つ(4アンサンブル)
- 0.947 +ダイクストラ法による後処理
Validationについて
前述した通り、LBのスコアが良かったため我々はfulldataによる学習を行いました。この結果として我々のCVは過学習のためLBより大きいものとなっています。一見すると問題を引き起こしそうですが、過学習してもなおCVとLBとの図のように線形関係は維持できており、CVを上げていくことでLBを上げることができました。
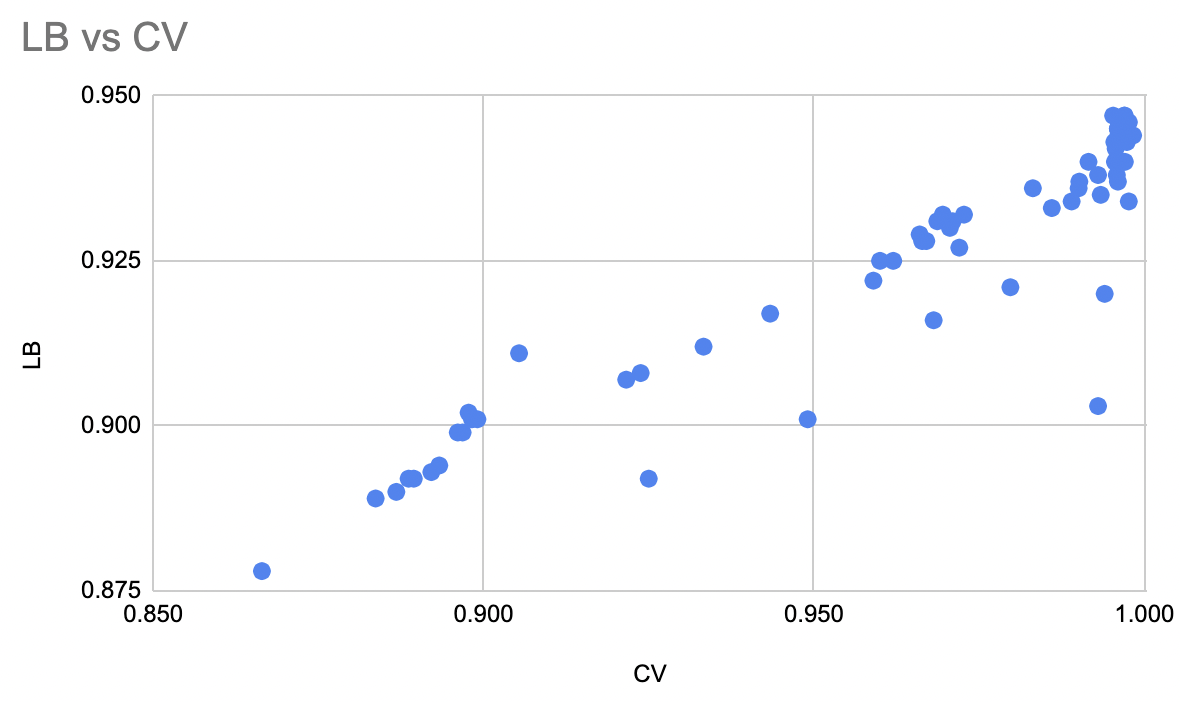
しかしコンペ終盤においてはこの方法は次のような問題を引き起こしました。
- CVが1.0付近で飽和してしまい、これ以上の改善が難しくなってしまいました。
- CVとLBの乖離からリークに気がつくチャンスを失っていました
計算環境について
我々のチームは十分なGPUを搭載した実機を持っていなかったためクラウドサービスを利用しました。コンペ序盤はGoogle Colabを使っていましたが、BERTを学習するのに十分な計算能力ではなかったため、Vast.aiを利用しました。他サービスと比べてGPUの割り当てがよく重宝していました。Vast.aiの料金に関しては会社から研修費として支援して頂き、大変助かりました。GBDTの学習に関してはKaggle Notebook上で行いました。
リークに関して
我々のチームはコンペ中にリークに気がつくことがなく、明示的には利用をしませんでした。しかしながらfulldata学習などを行なっており、過学習による暗黙的な恩恵は受けていたようです。
リークに関してはいくつか気がつけるヒントはあったため、観察眼が足りなかったと反省しています。
- テストデータのサンプルに学習データと同じ地点が含まれていた
- fulldata学習によりスコアが上がっていた
- GBDTのパラメタを過学習する過激なものにするとスコアが上がっていた
他のチームの解法について
他のチームの解法で良いと思ったものを共有します:
- 多段階に候補を絞り込んでいく解法
- 1st solution, 2nd solution
- 初めに候補を生成した後 (ex. 1st solutionだと200候補)、数段階に分けて徐々に候補を減らしながら重い判定モデルを使っています
- 各段階ごとのCVスコアやその後の処理が完璧だとして得られるスコア(max IoU)を計算しています
- モデルのどこを改善すれば良いか分かりやすくて、良いパイプラインと実験管理だなと思いました
- NN の学習が上手い解法
- 3rd solution
- ArcFace + Bi-Encoder. 凝った後処理など抜きで性能が高いのは NN の学習がうまくいってそうで今後参考にしたいです
- Word tour を用いた埋込の低次元化
- 7th solution
- 埋込点で巡回セールスマン問題を解き、訪問した順番を特徴量とすることで、埋込を情報を保ちつつ低次元化できるようです
- マッチ判定が面白いもの
- 13th solution
- リーク抜きだと2位でした
- GNNを使うことでダイクストラよりリッチなグラフ情報を使えています
- 12th solution
- 「n辺で到達できて最小距離がd(n)以下ならマッチ」というように、我々のダイクストラを用いた方法より精密な閾値判定をしています。
- 15th solution
- 地点のクラスタを作り、それらをうまくまとめ上げていくアルゴリズムを作っていました。グラフ情報を取り入れつつDBA的なこともできていそうで興味深いです。
- 13th solution
コンペを振り返ってみて
Kaggle自体に初参加だったこともあり、初めはNotebookの提出の方法すら知らないレベルでした。加えてベースラインで何をやっているかを読むのに1週間くらい溶かしたりして、最初のうちはチームに全然貢献できていない緊張感は抱えていました。ただこれは結果的には杞憂で、チームの皆さんは優しく色々な質問に答えてくれ早いうちに追いつくことができました。最終的にはダイクストラ周りの実験をいくつか回して、スコアを + 0.002上げて金ボーダーの戦いに貢献できたのは非常に楽しかったです。他チームがスコアを上げていくのをみて最後の週は戦々恐々としていましたが、幸い金メダルは維持できたのは良かったです。リーク自体は残念ですが、なかなか得難い経験でもあったなとポジティブにも捉えています。
他のチームメンバーの一言コメント
コンペに不手際があったことは残念ですが、NLP などのあまり触れたことのない分野をチームメイトや他チームのソリューションから多く学べて非常に有意義な体験でした。 私自身はまだまだ経験も浅いので、今後もコンペには積極的に参加して技術やノウハウを吸収して業務にも活かしていきたいと思います。 (データサイエンティスト 島村)
エムシーデジタルの皆さんと一緒に取り組んでとても楽しかったです。勉強も色々できました。 自分はDLモデル学習を工夫して大きく貢献できてよかったと思います。 これからGMになりたいです! (データサイエンティスト Artem)
チームメイトと色々議論しながら少しずつスコアを上げるなど楽しく取り組むことができました。 今後もGM目指してKaggleに取り組んでいきたいと思います。 (データサイエンティスト 齋藤)
タスク自体は多様なアプローチを考えることができ面白かったです。メンバーで色々アイディアを出し合いスコアを上げることができ楽しかったとともに非常に勉強になりました。 初めてのエムシーデジタルチームでの本格的なコンペ参加で金メダルを取れることができ良かったです! (データサイエンティスト 瀬川)
We are hiring!
エムシーデジタルではデータサイエンティストをはじめ様々な職種の方を募集しています。今回のコンペチームのような優秀なメンバーが揃っていますし、Kaggleに限らず様々な場面で、私のような初参加のメンバーが安心して挑戦できしかもサポートしてもらえる良い環境だと思っています。もし興味があれば是非カジュアル面談からでも受けていただけると嬉しいです。



